1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
from PIL import Image
import os, random, re
import pytesseract
fl = re.compile(r'[a-zA-Z-]+')
def clearStr(str):
return ''.join(fl.findall(str))
class Fileset(list):
def __init__(self, name, ext='', _read=None, root=None):
if isinstance(name, str) :
self.root = os.path.join(root or os.getcwd(), name)
self.extend(f for f in os.listdir(self.root) if f.endswith(ext))
self._read = _read
def __getitem__(self, index):
if isinstance(index, int):
return os.path.join(self.root, super().__getitem__(index))
else:
fileset = Fileset(None)
fileset.root = self.root
fileset._read = self._read
fileset.extend(super().__getitem__(index))
return fileset
def getFileName(self, index):
fname, ext = os.path.splitext(super().__getitem__(index))
return fname
def __iter__(self):
if self._read: return (self._read(os.path.join(self.root, f)) for f in super().__iter__())
else: return (os.path.join(self.root, f) for f in super().__iter__())
def __call__(self):
retn = random.choice(self)
if self._read: return self._read(retn)
else: return retn
sample = Fileset('Captcha', '.jpg', Image.open)
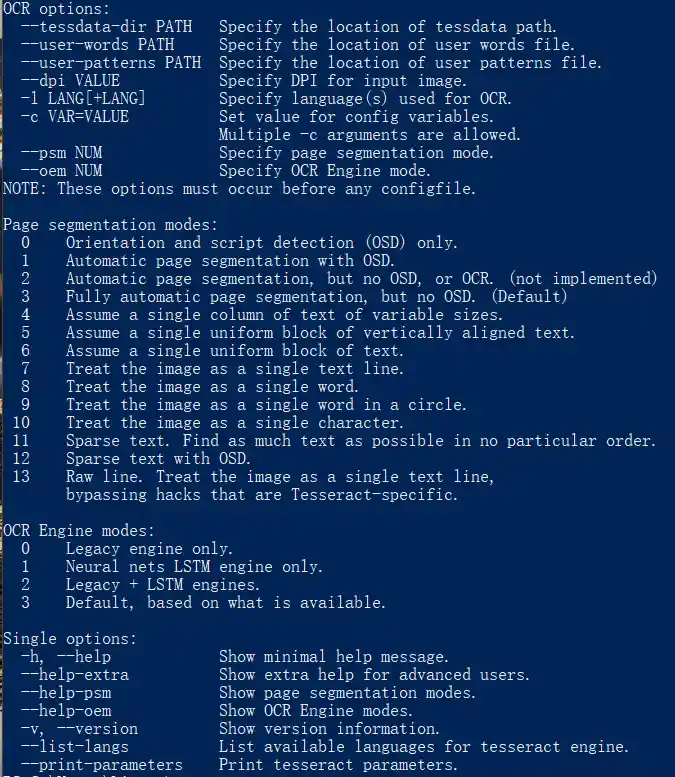
config1 = '--psm 8'
def OCR1(img):
return pytesseract.image_to_string(img, lang='fdu', config=config1)
config2 = "--psm 8 --oem 0 -c tessedit_char_whitelist=abcdefghijklmnopqrstuvwxyzAT-"
def OCR2(img):
return pytesseract.image_to_string(img, lang='eng', config=config2)
for a in sample:
b = a.convert("L")
x = clearStr(OCR1(b))
y = clearStr(OCR2(b))
if x != y:
display(a)
print(f"LSTM is {x} ; Legacy is {y}")
|