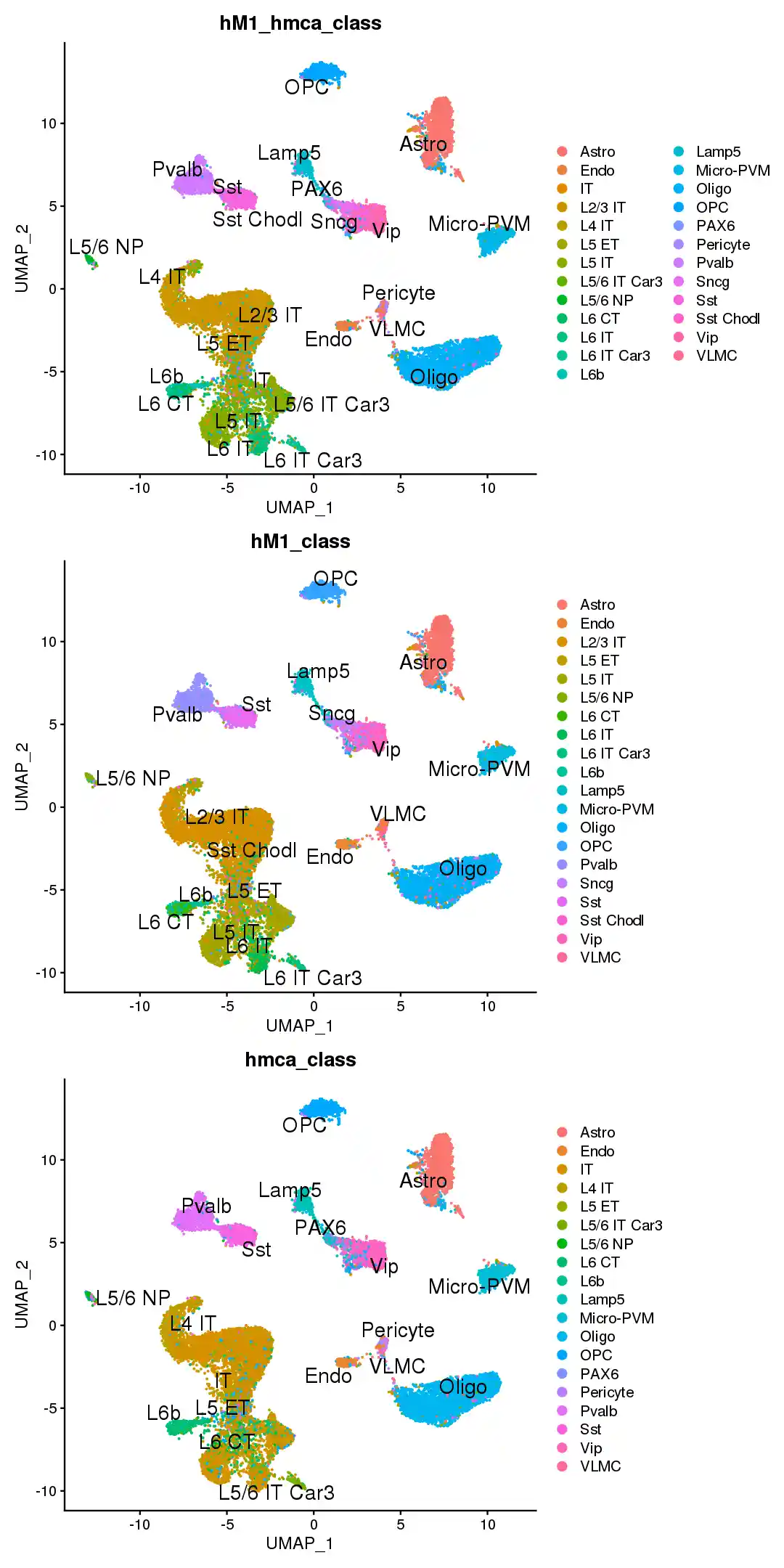
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
|
library(Seurat)
library(dplyr)
library(patchwork)
library(SingleR)
library(SummarizedExperiment)
library(scater)
library(BiocParallel) # 并行计算加速
root_path = "/home/rqzhang/rqzhang"
output_path = "~/zlliu/R_output/21.09.21.SingleR"
if (!file.exists(output_path)){dir.create(output_path)}
setwd(output_path)
getwd()
scRNA = readRDS("/home/rqzhang/rqzhang/SC_gene_integrate.rds")
if (!("hM1.se" %in% ls())){
hM1.se <- readRDS("/home/rqzhang/zlliu/R_data/human_M1_10x/hM1.se.rds")
}
if (!("hmca" %in% ls())){
hmca <- readRDS("/home/rqzhang/zlliu/R_data/Human_Multiple_Cortical_Areas_SMART-seq/hmca.rds")
}
f_noNull <- function(lc_se, lc_col){
if(any(lc_se$meta["sample_name"] != colnames(lc_se))){
return
}
lc_idx = which(lc_se$meta[lc_col] == "")
lc_res = lc_se[, -lc_idx]
lc_res$meta = lc_se$meta[-lc_idx,]
lc_res
}
hmca <- f_noNull(hmca, "subclass_label")
f_listUpdateRe <- function(lc_obj, lc_bool, lc_item){
lc_obj[lc_bool] <- rep(lc_item,times=sum(lc_bool))
lc_obj
}
f_subSameName <- function(lc_obj, lc_name_x, lc_name_y){
for (lc_i in 1:length(lc_name_x)){
lc_x = lc_name_x[lc_i]
lc_y = lc_name_y[lc_i]
lc_idx = (lc_obj == lc_x)
lc_obj = f_listUpdateRe(lc_obj , lc_idx, lc_y)
}
lc_obj
}
hM1.se$meta$subclass_label <- f_subSameName(hM1.se$meta$subclass_label,
c('Astrocyte', 'Endothelial', 'LAMP5', 'Microglia', 'Oligodendrocyte', 'PVALB', 'SST', 'VIP'),
c('Astro', 'Endo', 'Lamp5', 'Micro-PVM', 'Oligo', 'Pvalb', 'Sst', 'Vip'))
hmca$meta$subclass_label <- f_subSameName(hmca$meta$subclass_label,
c('Astrocyte', 'Endothelial', 'LAMP5', 'Microglia', 'Oligodendrocyte', 'PVALB', 'SST', 'VIP'),
c('Astro', 'Endo', 'Lamp5', 'Micro-PVM', 'Oligo', 'Pvalb', 'Sst', 'Vip'))
data_for_SingleR = scRNA[["integrated"]]@data
common_gene <- intersect(rownames(data_for_SingleR), c(rownames(hM1.se), rownames(hmca)))
data_for_SingleR <- data_for_SingleR[common_gene,]
tp_idx = na.omit(match(common_gene, rownames(hM1.se)))
lc_hM1.se <- hM1.se[rownames(hM1.se)[tp_idx], ]
tp_idx = na.omit(match(common_gene, rownames(hmca)))
lc_hmca <- hmca[rownames(hmca)[tp_idx], ]
pred_1 <- SingleR(test = data_for_SingleR, ref = list(m1=lc_hM1.se, mca=lc_hmca),
labels = list(hM1.se$meta$subclass_label, hmca$meta$subclass_label),
BPPARAM=MulticoreParam(32)) # 32CPUs
pred_2 <- SingleR(test = data_for_SingleR, ref = lc_hM1.se,
labels = hM1.se$meta$subclass_label,
BPPARAM=MulticoreParam(32)) # 32CPUs
pred_3 <- SingleR(test = data_for_SingleR, ref = lc_hmca,
labels = hmca$meta$subclass_label,
BPPARAM=MulticoreParam(32)) # 32CPUs
f_merge <- function(lc_mergedList){
Reduce(function(...) merge(..., by="CB"), lc_mergedList)
}
f_pred2meta <- function(lc_pred, lc_colname){
lc_result <- as.data.frame(lc_pred$labels)
lc_result$CB <- rownames(lc_pred)
colnames(lc_result) <- c(lc_colname, 'CB')
lc_result
}
pred_1 <- f_pred2meta(pred_1, "hM1_hmca_class")
pred_2 <- f_pred2meta(pred_2, "hM1_class")
pred_3 <- f_pred2meta(pred_3, "hmca_class")
|