1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
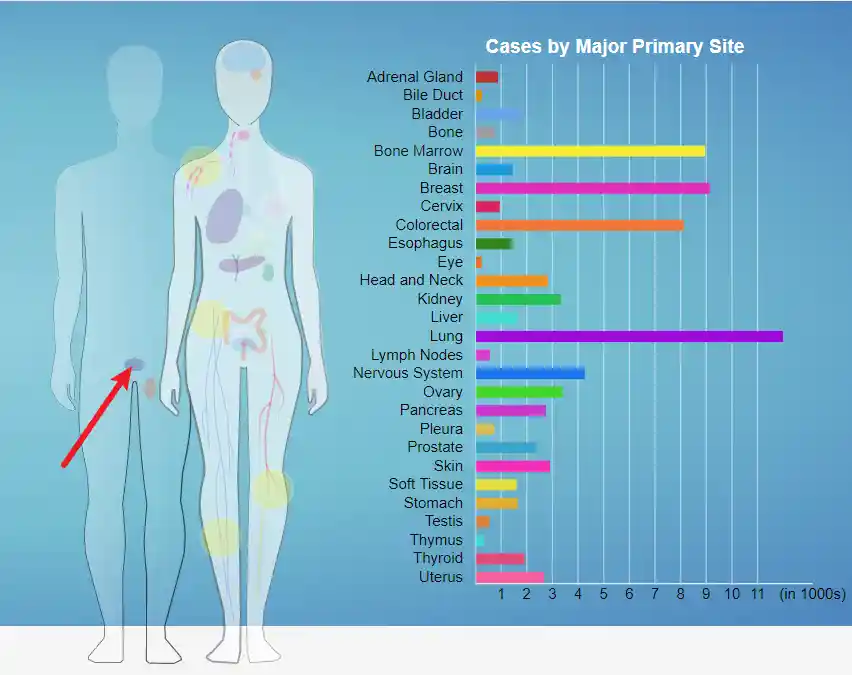
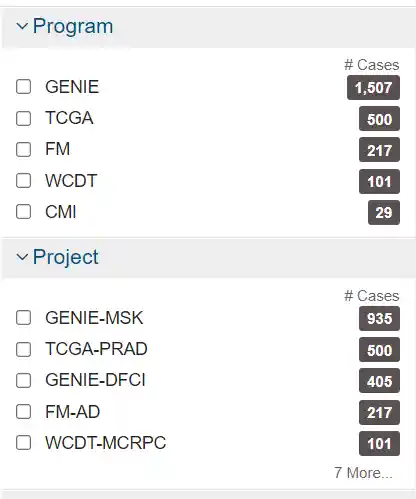
| # 一般的前列腺癌 GDC Data Portal 是 hg38 的
PRAD <- GDCquery(project = 'TCGA-PRAD',
data.category = "Transcriptome Profiling",
data.type = "Gene Expression Quantification",
workflow.type = "HTSeq - Counts")
# mCRPC
mCRPC <- GDCquery(project = 'WCDT-MCRPC',
data.category = "Transcriptome Profiling",
data.type = "Gene Expression Quantification",
workflow.type = "HTSeq - Counts")
# 选择病例列 ,不加cols参数则是完整结果的全部列
PRAD_cases <- getResults(PRAD,cols=c("cases"))
mCRPC_cases <- getResults(mCRPC,cols=c("cases"))
# 选择癌组织数据
PRAD_tp <- TCGAquery_SampleTypes(barcode = PRAD_cases, typesample = "TP")
PRAD_D <- GDCquery(project = 'TCGA-PRAD',
data.category = "Transcriptome Profiling",
data.type = "Gene Expression Quantification",
workflow.type = "HTSeq - Counts",
barcode = PRAD_tp)
mCRPC_D <- GDCquery(project = 'WCDT-MCRPC',
data.category = "Transcriptome Profiling",
data.type = "Gene Expression Quantification",
workflow.type = "HTSeq - Counts",
sample.type = "Metastatic", #下载癌组织的数据
barcode = mCRPC_cases)
saveRDS(PRAD_D,"PRAD_D.rds")
saveRDS(mCRPC_D,"mCRPC_D.rds")
GDCdownload(query = PRAD_D)
GDCdownload(query = mCRPC_D)
PRAD_pre1 <- GDCprepare(query = PRAD_D, save = TRUE, save.filename = "PRAD_pre1.rda")
mCRPC_pre1 <- GDCprepare(query = mCRPC_D, save = TRUE, save.filename = "mCRPC_pre1.rda")
# 导出counts矩阵
PRAD_pre <- PRAD_pre1@assays@data$`HTSeq - Counts`
colnames(PRAD_pre) <- PRAD_pre1@colData@rownames
rownames(PRAD_pre) <- PRAD_pre1@rowRanges$external_gene_name
mCRPC_pre <- mCRPC_pre1@assays@data$`HTSeq - Counts`
colnames(mCRPC_pre) <- mCRPC_pre1@colData@rownames
rownames(mCRPC_pre) <- mCRPC_pre1@rowRanges$external_gene_name
|